Chapter 8 Cross-annotating human pancreas
8.1 Loading the data
We load the Muraro et al. (2016) dataset as our reference, removing unlabelled cells or cells without a clear label.
library(scRNAseq)
sceM <- MuraroPancreasData()
sceM <- sceM[,!is.na(sceM$label) & sceM$label!="unclear"] We compute log-expression values for use in marker detection inside SingleR().
We examine the distribution of labels in this reference.
##
## acinar alpha beta delta duct endothelial
## 219 812 448 193 245 21
## epsilon mesenchymal pp
## 3 80 101We load the Grun et al. (2016) dataset as our test, applying some basic quality control to remove low-quality cells in some of the batches (see here for details).
sceG <- GrunPancreasData()
sceG <- addPerCellQC(sceG)
qc <- quickPerCellQC(colData(sceG),
percent_subsets="altexps_ERCC_percent",
batch=sceG$donor,
subset=sceG$donor %in% c("D17", "D7", "D2"))
sceG <- sceG[,!qc$discard]Technically speaking, the test dataset does not need log-expression values but we compute them anyway for convenience.
8.2 Applying the annotation
We apply SingleR() with Wilcoxon rank sum test-based marker detection to annotate the Grun dataset with the Muraro labels.
We examine the distribution of predicted labels:
##
## acinar alpha beta delta duct endothelial
## 289 201 178 54 295 5
## epsilon mesenchymal pp
## 1 23 18We can also examine the number of discarded cells for each label:
## Lost
## Label FALSE TRUE
## acinar 260 29
## alpha 200 1
## beta 177 1
## delta 52 2
## duct 291 4
## endothelial 5 0
## epsilon 1 0
## mesenchymal 22 1
## pp 18 08.3 Diagnostics
We visualize the assignment scores for each label in Figure 8.1.
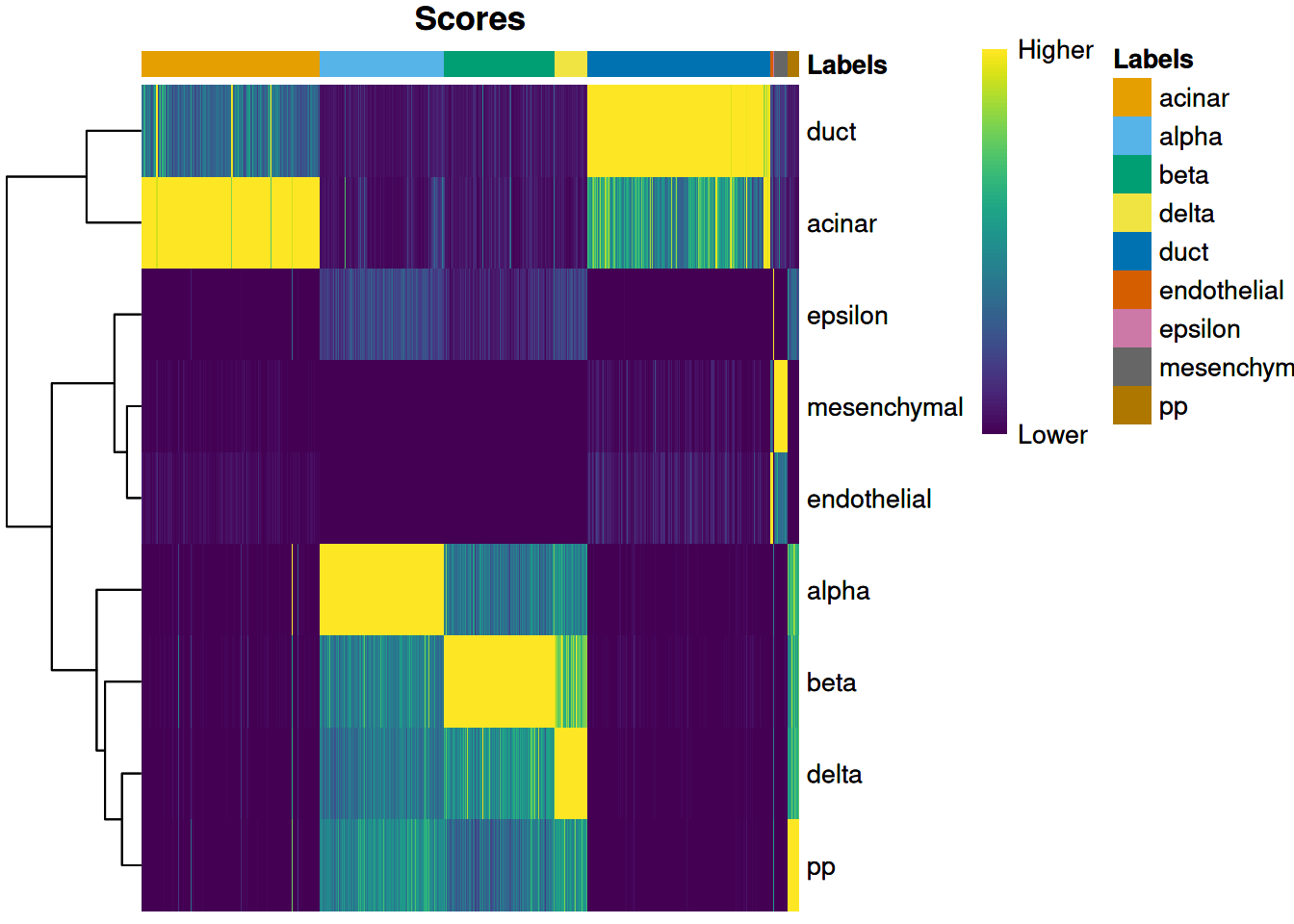
Figure 8.1: Heatmap of the (normalized) assignment scores for each cell (column) in the Grun test dataset with respect to each label (row) in the Muraro reference dataset. The final assignment for each cell is shown in the annotation bar at the top.
The delta for each cell is visualized in Figure 8.2.
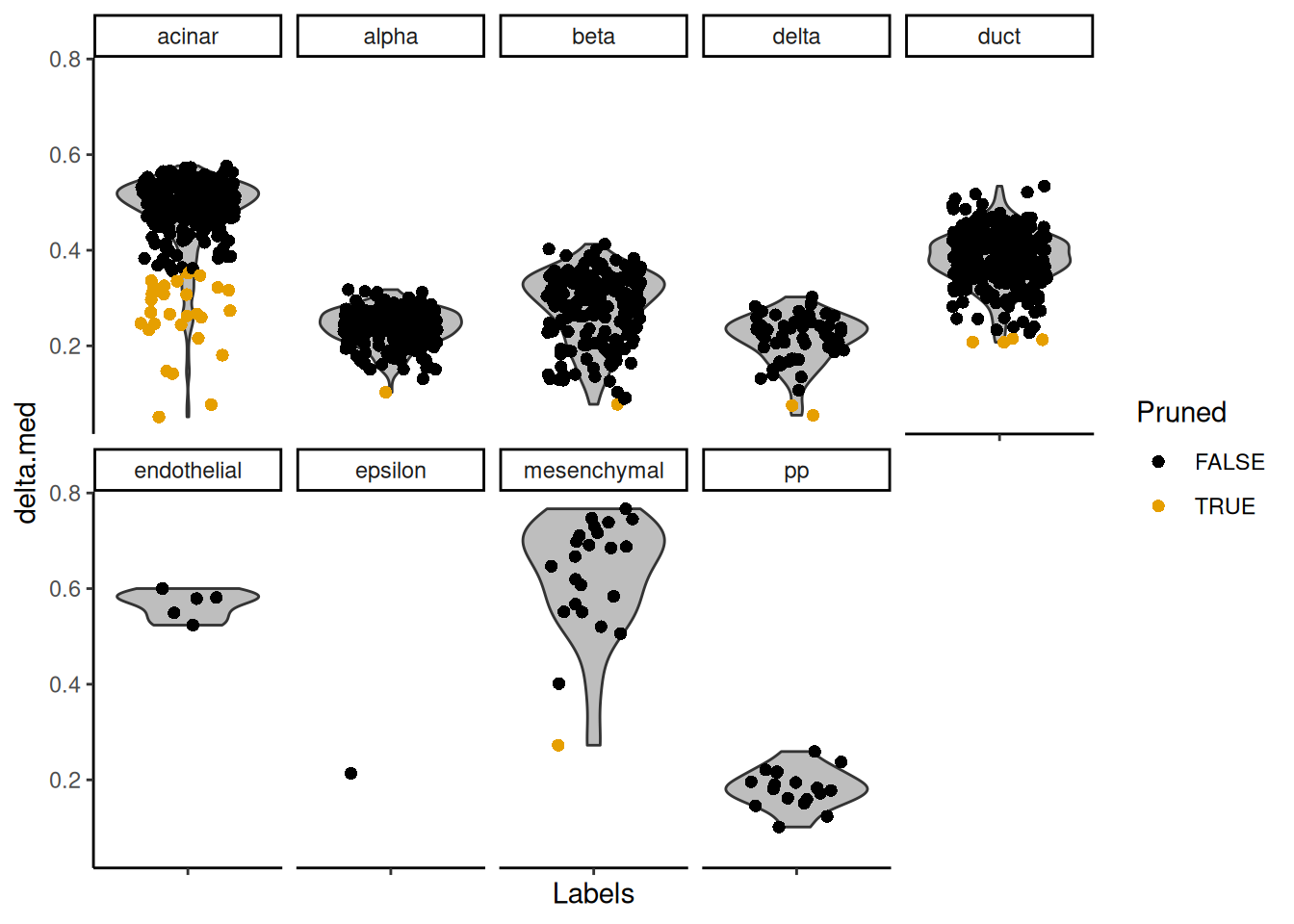
Figure 8.2: Distributions of the deltas for each cell in the Grun dataset assigned to each label in the Muraro dataset. Each cell is represented by a point; low-quality assignments that were pruned out are colored in orange.
Finally, we visualize the heatmaps of the marker genes for each label in Figure 8.3.
library(scater)
collected <- list()
all.markers <- metadata(pred.grun)$de.genes
sceG$labels <- pred.grun$labels
for (lab in unique(pred.grun$labels)) {
collected[[lab]] <- plotHeatmap(sceG, silent=TRUE,
order_columns_by="labels", main=lab,
features=unique(unlist(all.markers[[lab]])))[[4]]
}
do.call(gridExtra::grid.arrange, collected)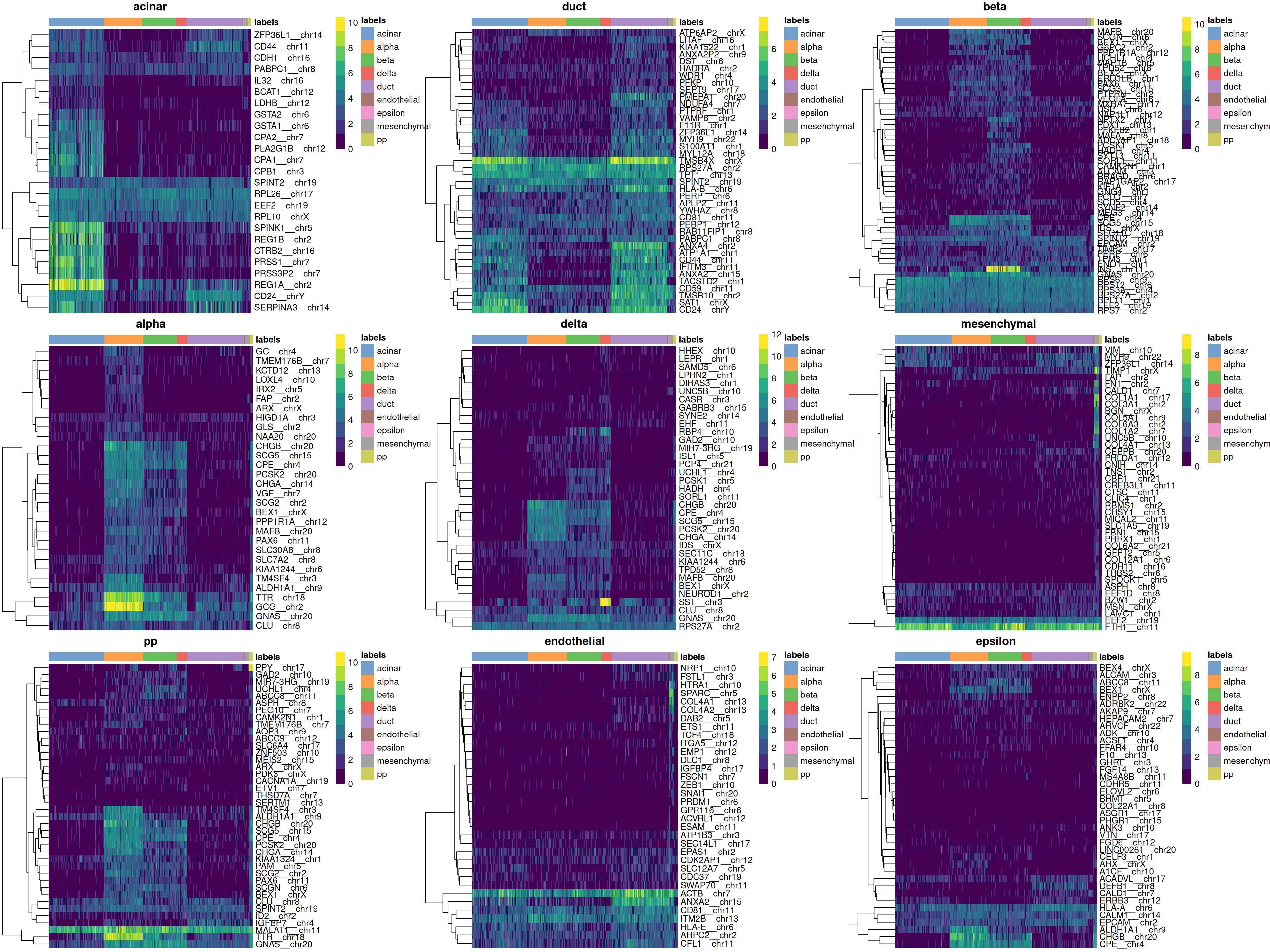
Figure 8.3: Heatmaps of log-expression values in the Grun dataset for all marker genes upregulated in each label in the Muraro reference dataset. Assigned labels for each cell are shown at the top of each plot.
8.4 Comparison to clusters
For comparison, we will perform a quick unsupervised analysis of the Grun dataset.
We model the variances using the spike-in data and we perform graph-based clustering
(increasing the resolution by dropping k=5).
library(scran)
decG <- modelGeneVarWithSpikes(sceG, "ERCC")
set.seed(1000100)
sceG <- denoisePCA(sceG, decG)
library(bluster)
sceG$cluster <- clusterRows(reducedDim(sceG), NNGraphParam(k=5))We see that the clusters map reasonably well to the labels in Figure 8.4.
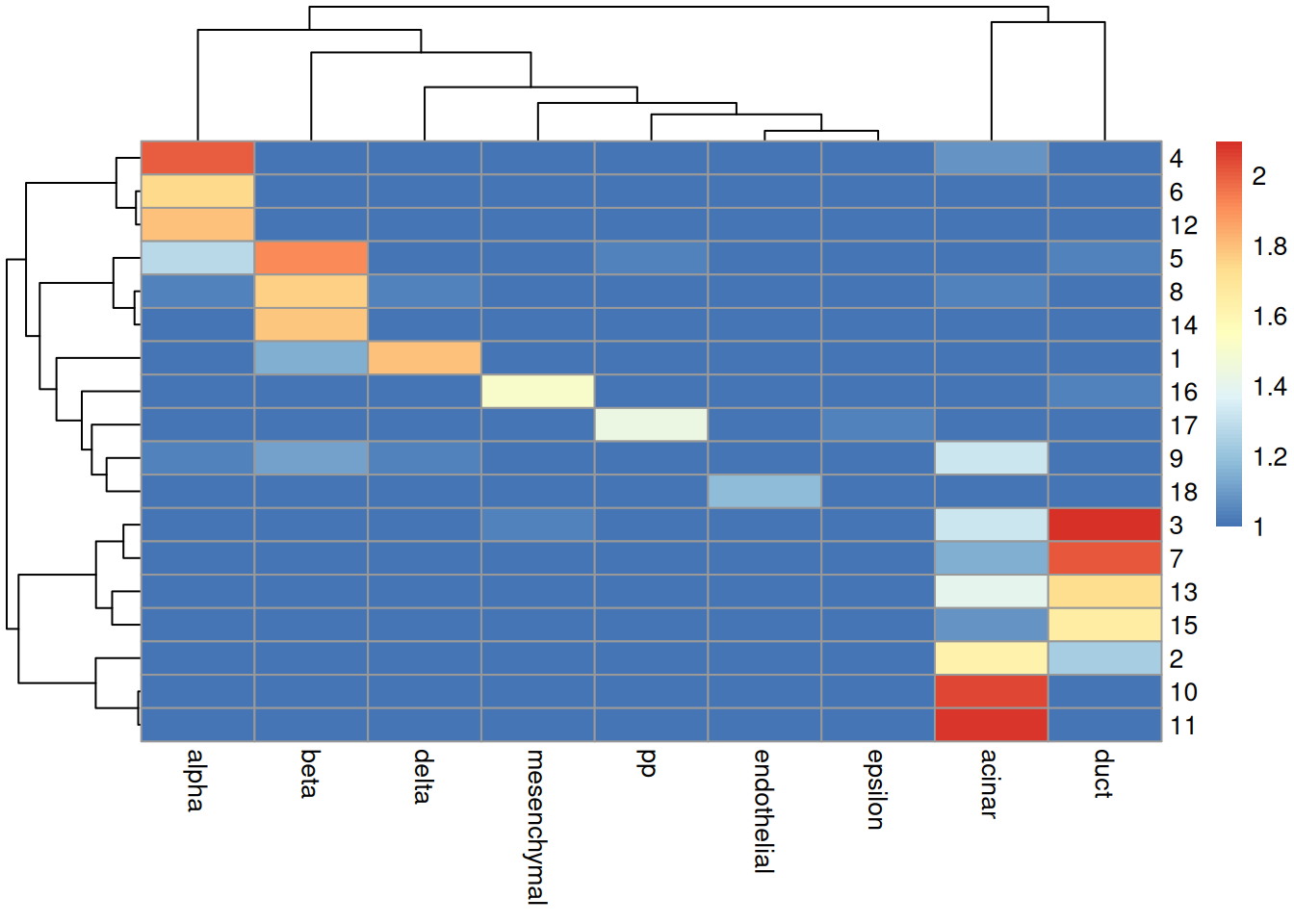
Figure 8.4: Heatmap of the log-transformed number of cells in each combination of label (column) and cluster (row) in the Grun dataset.
We proceed to the most important part of the analysis. Yes, that’s right, the \(t\)-SNE plot (Figure 8.5).
set.seed(101010100)
sceG <- runTSNE(sceG, dimred="PCA")
plotTSNE(sceG, colour_by="cluster", text_colour="red",
text_by=I(pred.grun$labels))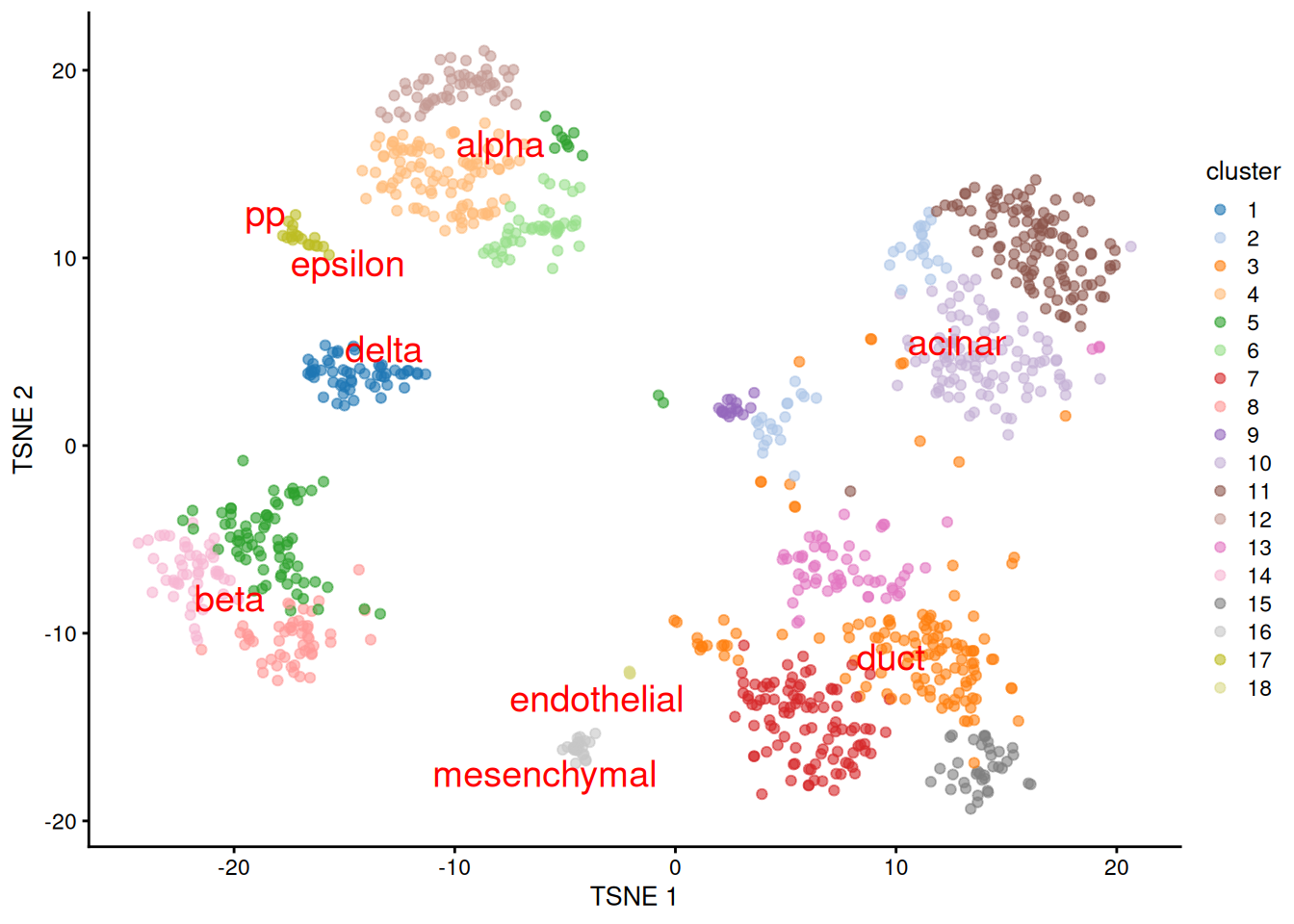
Figure 8.5: \(t\)-SNE plot of the Grun dataset, where each point is a cell and is colored by the assigned cluster. Reference labels from the Muraro dataset are also placed on the median coordinate across all cells assigned with that label.
Session information
R version 4.5.0 RC (2025-04-04 r88126)
Platform: x86_64-pc-linux-gnu
Running under: Ubuntu 24.04.2 LTS
Matrix products: default
BLAS: /home/biocbuild/bbs-3.21-bioc/R/lib/libRblas.so
LAPACK: /usr/lib/x86_64-linux-gnu/lapack/liblapack.so.3.12.0 LAPACK version 3.12.0
locale:
[1] LC_CTYPE=en_US.UTF-8 LC_NUMERIC=C
[3] LC_TIME=en_GB LC_COLLATE=C
[5] LC_MONETARY=en_US.UTF-8 LC_MESSAGES=en_US.UTF-8
[7] LC_PAPER=en_US.UTF-8 LC_NAME=C
[9] LC_ADDRESS=C LC_TELEPHONE=C
[11] LC_MEASUREMENT=en_US.UTF-8 LC_IDENTIFICATION=C
time zone: America/New_York
tzcode source: system (glibc)
attached base packages:
[1] stats4 stats graphics grDevices utils datasets methods
[8] base
other attached packages:
[1] bluster_1.18.0 scran_1.36.0
[3] SingleR_2.10.0 scater_1.36.0
[5] ggplot2_3.5.2 scuttle_1.18.0
[7] scRNAseq_2.21.1 SingleCellExperiment_1.30.0
[9] SummarizedExperiment_1.38.0 Biobase_2.68.0
[11] GenomicRanges_1.60.0 GenomeInfoDb_1.44.0
[13] IRanges_2.42.0 S4Vectors_0.46.0
[15] BiocGenerics_0.54.0 generics_0.1.3
[17] MatrixGenerics_1.20.0 matrixStats_1.5.0
[19] BiocStyle_2.36.0 rebook_1.18.0
loaded via a namespace (and not attached):
[1] RColorBrewer_1.1-3 jsonlite_2.0.0
[3] CodeDepends_0.6.6 magrittr_2.0.3
[5] ggbeeswarm_0.7.2 GenomicFeatures_1.60.0
[7] gypsum_1.4.0 farver_2.1.2
[9] rmarkdown_2.29 BiocIO_1.18.0
[11] vctrs_0.6.5 DelayedMatrixStats_1.30.0
[13] memoise_2.0.1 Rsamtools_2.24.0
[15] RCurl_1.98-1.17 htmltools_0.5.8.1
[17] S4Arrays_1.8.0 AnnotationHub_3.16.0
[19] curl_6.2.2 BiocNeighbors_2.2.0
[21] Rhdf5lib_1.30.0 SparseArray_1.8.0
[23] rhdf5_2.52.0 sass_0.4.10
[25] alabaster.base_1.8.0 bslib_0.9.0
[27] alabaster.sce_1.8.0 httr2_1.1.2
[29] cachem_1.1.0 GenomicAlignments_1.44.0
[31] igraph_2.1.4 lifecycle_1.0.4
[33] pkgconfig_2.0.3 rsvd_1.0.5
[35] Matrix_1.7-3 R6_2.6.1
[37] fastmap_1.2.0 GenomeInfoDbData_1.2.14
[39] digest_0.6.37 colorspace_2.1-1
[41] AnnotationDbi_1.70.0 dqrng_0.4.1
[43] irlba_2.3.5.1 ExperimentHub_2.16.0
[45] RSQLite_2.3.9 beachmat_2.24.0
[47] labeling_0.4.3 filelock_1.0.3
[49] httr_1.4.7 abind_1.4-8
[51] compiler_4.5.0 bit64_4.6.0-1
[53] withr_3.0.2 BiocParallel_1.42.0
[55] viridis_0.6.5 DBI_1.2.3
[57] HDF5Array_1.36.0 alabaster.ranges_1.8.0
[59] alabaster.schemas_1.8.0 rappdirs_0.3.3
[61] DelayedArray_0.34.0 rjson_0.2.23
[63] tools_4.5.0 vipor_0.4.7
[65] beeswarm_0.4.0 glue_1.8.0
[67] h5mread_1.0.0 restfulr_0.0.15
[69] rhdf5filters_1.20.0 grid_4.5.0
[71] Rtsne_0.17 cluster_2.1.8.1
[73] gtable_0.3.6 ensembldb_2.32.0
[75] metapod_1.16.0 BiocSingular_1.24.0
[77] ScaledMatrix_1.16.0 XVector_0.48.0
[79] ggrepel_0.9.6 BiocVersion_3.21.1
[81] pillar_1.10.2 limma_3.64.0
[83] dplyr_1.1.4 BiocFileCache_2.16.0
[85] lattice_0.22-7 rtracklayer_1.68.0
[87] bit_4.6.0 tidyselect_1.2.1
[89] locfit_1.5-9.12 Biostrings_2.76.0
[91] knitr_1.50 gridExtra_2.3
[93] scrapper_1.2.0 bookdown_0.43
[95] ProtGenerics_1.40.0 edgeR_4.6.0
[97] xfun_0.52 statmod_1.5.0
[99] pheatmap_1.0.12 UCSC.utils_1.4.0
[101] lazyeval_0.2.2 yaml_2.3.10
[103] evaluate_1.0.3 codetools_0.2-20
[105] tibble_3.2.1 alabaster.matrix_1.8.0
[107] BiocManager_1.30.25 graph_1.86.0
[109] cli_3.6.4 munsell_0.5.1
[111] jquerylib_0.1.4 Rcpp_1.0.14
[113] dir.expiry_1.16.0 dbplyr_2.5.0
[115] png_0.1-8 XML_3.99-0.18
[117] parallel_4.5.0 blob_1.2.4
[119] AnnotationFilter_1.32.0 sparseMatrixStats_1.20.0
[121] bitops_1.0-9 viridisLite_0.4.2
[123] alabaster.se_1.8.0 scales_1.3.0
[125] crayon_1.5.3 rlang_1.1.6
[127] cowplot_1.1.3 KEGGREST_1.48.0 Bibliography
Grun, D., M. J. Muraro, J. C. Boisset, K. Wiebrands, A. Lyubimova, G. Dharmadhikari, M. van den Born, et al. 2016. “De Novo Prediction of Stem Cell Identity using Single-Cell Transcriptome Data.” Cell Stem Cell 19 (2): 266–77.
Muraro, M. J., G. Dharmadhikari, D. Grun, N. Groen, T. Dielen, E. Jansen, L. van Gurp, et al. 2016. “A Single-Cell Transcriptome Atlas of the Human Pancreas.” Cell Syst 3 (4): 385–94.