---
output:
html_document
bibliography: ref.bib
---
# Doublet detection
## Overview
In single-cell RNA sequencing (scRNA-seq) experiments, doublets are artifactual libraries generated from two cells.
They typically arise due to errors in cell sorting or capture, especially in droplet-based protocols [@zheng2017massively] involving thousands of cells.
Doublets are obviously undesirable when the aim is to characterize populations at the single-cell level.
In particular, doublets can be mistaken for intermediate populations or transitory states that do not actually exist.
Thus, it is desirable to identify and remove doublet libraries so that they do not compromise interpretation of the results.
Several experimental strategies are available for doublet removal.
One approach exploits natural genetic variation when pooling cells from multiple donor individuals [@kang2018multiplexed].
Doublets can be identified as libraries with allele combinations that do not exist in any single donor.
Another approach is to mark a subset of cells (e.g., all cells from one sample) with an antibody conjugated to a different oligonucleotide [@stoeckius2018hashing].
Upon pooling, libraries that are observed to have different oligonucleotides are considered to be doublets and removed.
These approaches can be highly effective but rely on experimental information that may not be available.
A more general approach is to infer doublets from the expression profiles alone [@dahlin2018single].
In this workflow, we will describe two purely computational approaches for detecting doublets from scRNA-seq data.
The main difference between these two methods is whether or not they need cluster information beforehand.
We will demonstrate the use of these methods on 10X Genomics data from a droplet-based scRNA-seq study of the mouse mammary gland [@bach2017differentiation].
``` r
sce.mam
```
```
## class: SingleCellExperiment
## dim: 27998 2772
## metadata(0):
## assays(2): counts logcounts
## rownames(27998): Xkr4 Gm1992 ... Vmn2r122 CAAA01147332.1
## rowData names(3): Ensembl Symbol SEQNAME
## colnames: NULL
## colData names(5): Barcode Sample Condition sizeFactor label
## reducedDimNames(2): PCA TSNE
## mainExpName: NULL
## altExpNames(0):
```
## Doublet detection with clusters
The `findDoubletClusters()` function from the *[scDblFinder](https://bioconductor.org/packages/3.19/scDblFinder)* package identifies clusters with expression profiles lying between two other clusters [@bach2017differentiation].
We consider every possible triplet of clusters consisting of a query cluster and two putative "source" clusters.
Under the null hypothesis that the query consists of doublets from the two sources, we compute the number of genes (`num.de`) that are differentially expressed in the same direction in the query cluster compared to _both_ of the source clusters.
Such genes would be unique markers for the query cluster and provide evidence against the null hypothesis.
For each query cluster, the best pair of putative sources is identified based on the lowest `num.de`.
Clusters are then ranked by `num.de` where those with the few unique genes are more likely to be composed of doublets.
``` r
# Like 'findMarkers', this function will automatically
# retrieve cluster assignments from 'colLabels'.
library(scDblFinder)
dbl.out <- findDoubletClusters(sce.mam)
dbl.out
```
```
## DataFrame with 10 rows and 9 columns
## source1 source2 num.de median.de best p.value
##
## 6 3 1 8 522.5 Fabp3 1.70911e-03
## 2 10 4 76 737.0 Xist 3.84476e-17
## 8 10 5 135 490.5 Gde1 1.80429e-11
## 3 8 6 140 975.0 Cotl1 1.10778e-07
## 10 8 7 193 392.0 Gpx3 1.10908e-19
## 5 8 7 270 771.5 C1qb 9.41842e-49
## 9 8 7 300 518.0 Fabp4 2.21523e-32
## 7 10 9 388 687.5 Col1a1 6.82664e-32
## 4 8 2 468 1604.5 Cdc20 7.00502e-72
## 1 7 6 539 1845.5 Acta2 2.75356e-25
## lib.size1 lib.size2 prop
##
## 6 0.792415 0.523830 0.03174603
## 2 0.613116 1.401351 0.30555556
## 8 1.125474 1.167854 0.00793651
## 3 0.572162 1.261965 0.23051948
## 10 0.888514 0.888432 0.00865801
## 5 0.856271 0.856192 0.01948052
## 9 0.655685 0.655624 0.01154401
## 7 1.125578 1.525264 0.01406926
## 4 0.388741 0.713597 0.17207792
## 1 0.865449 1.909018 0.19841270
```
If a more concrete threshold is necessary, we can identify clusters that have unusually low `num.de` using an outlier-based approach.
``` r
library(scater)
chosen.doublet <- rownames(dbl.out)[isOutlier(dbl.out$num.de, type="lower", log=TRUE)]
chosen.doublet
```
```
## [1] "6"
```
The function also reports the ratio of the median library size in each source to the median library size in the query (`lib.size` fields).
Ideally, a potential doublet cluster would have ratios lower than unity; this is because doublet libraries are generated from a larger initial pool of RNA compared to libraries for single cells, and thus the former should have larger library sizes.
The proportion of cells in the query cluster should also be reasonable - typically less than 5% of all cells, depending on how many cells were loaded onto the 10X Genomics device.
Examination of the `findDoubletClusters()` output indicates that cluster 6 has the fewest unique genes and library sizes that are comparable to or greater than its sources.
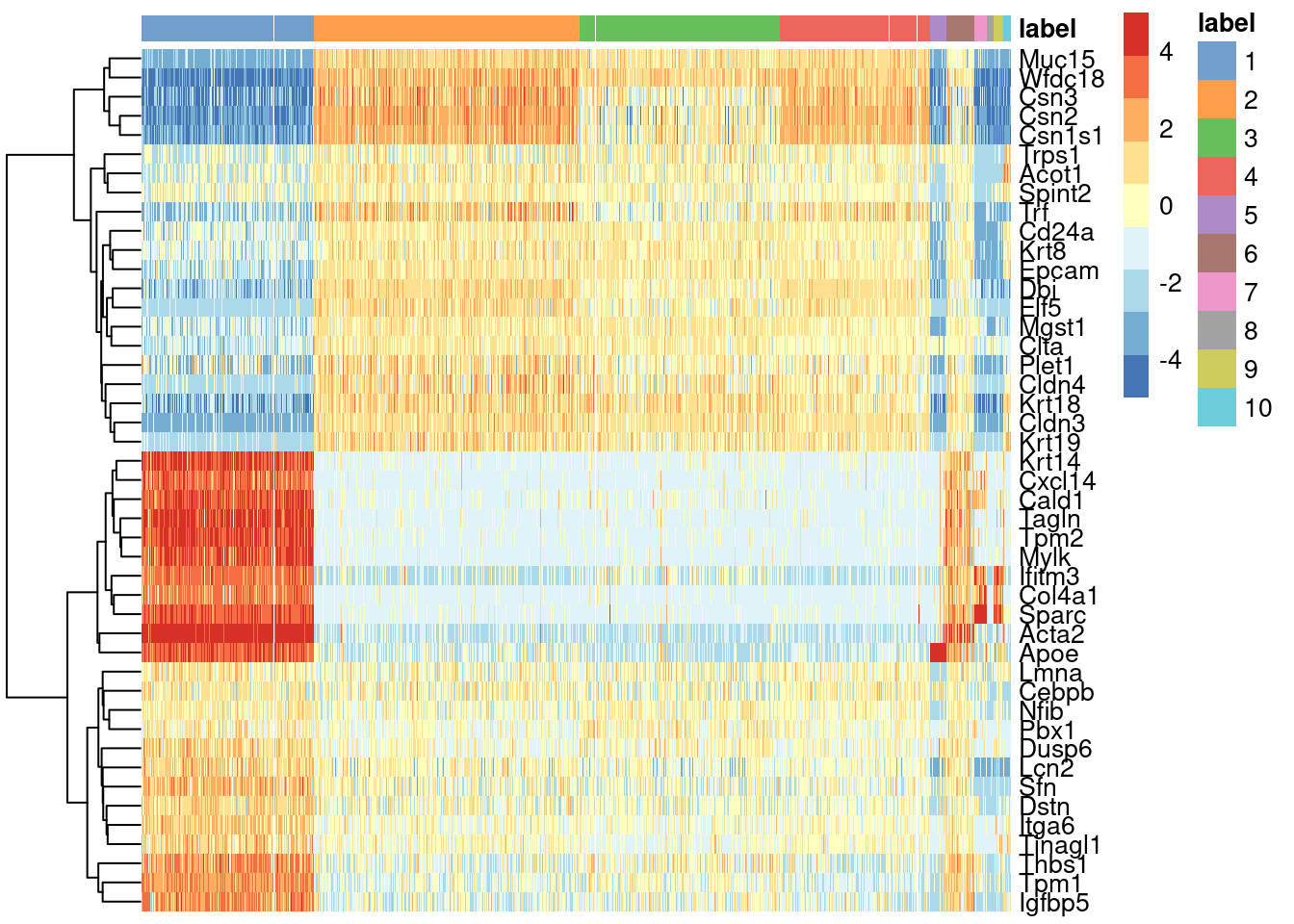
We see that every gene detected in this cluster is also expressed in either of the two proposed source clusters (Figure \@ref(fig:heatclust)).
``` r
library(scran)
markers <- findMarkers(sce.mam, direction="up")
dbl.markers <- markers[[chosen.doublet]]
library(scater)
chosen <- rownames(dbl.markers)[dbl.markers$Top <= 10]
plotHeatmap(sce.mam, order_columns_by="label", features=chosen,
center=TRUE, symmetric=TRUE, zlim=c(-5, 5))
```
(\#fig:heatclust)Heatmap of mean-centered and normalized log-expression values for the top set of markers for cluster 6 in the mammary gland dataset. Column colours represent the cluster to which each cell is assigned, as indicated by the legend.
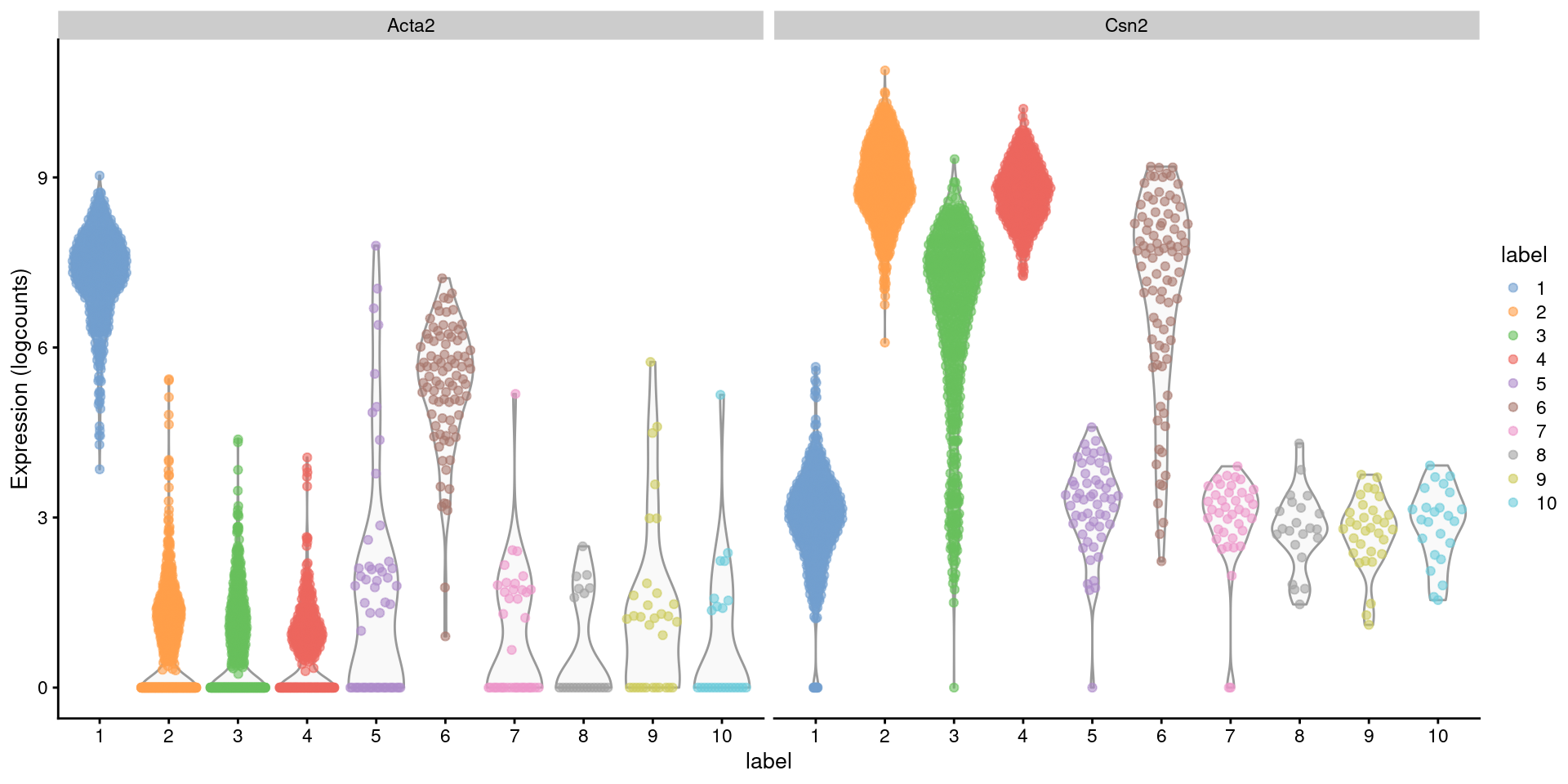
Closer examination of some known markers suggests that the offending cluster consists of doublets of basal cells (_Acta2_) and alveolar cells (_Csn2_) (Figure \@ref(fig:markerexprs)).
Indeed, no cell type is known to strongly express both of these genes at the same time, which supports the hypothesis that this cluster consists solely of doublets rather than being an entirely novel cell type.
``` r
plotExpression(sce.mam, features=c("Acta2", "Csn2"),
x="label", colour_by="label")
```
(\#fig:markerexprs)Distribution of log-normalized expression values for _Acta2_ and _Csn2_ in each cluster. Each point represents a cell.
The strength of `findDoubletClusters()` lies in its simplicity and ease of interpretation.
Suspect clusters can be quickly flagged based on the metrics returned by the function.
However, it is obviously dependent on the quality of the clustering.
Clusters that are too coarse will fail to separate doublets from other cells, while clusters that are too fine will complicate interpretation.
The method is also somewhat biased towards clusters with fewer cells, where the reduction in power is more likely to result in a low `N`.
(Fortunately, this is a desirable effect as doublets should be rare in a properly performed scRNA-seq experiment.)
## Doublet detection by simulation {#doublet-simulation}
### Computing doublet densities
The other doublet detection strategy involves _in silico_ simulation of doublets from the single-cell expression profiles [@dahlin2018single].
This is performed using the `computeDoubletDensity()` function from *[scDblFinder](https://bioconductor.org/packages/3.19/scDblFinder)*, which will:
1. Simulate thousands of doublets by adding together two randomly chosen single-cell profiles.
2. For each original cell, compute the density of simulated doublets in the surrounding neighborhood.
3. For each original cell, compute the density of other observed cells in the neighborhood.
4. Return the ratio between the two densities as a "doublet score" for each cell.
This approach assumes that the simulated doublets are good approximations for real doublets.
The use of random selection accounts for the relative abundances of different subpopulations, which affect the likelihood of their involvement in doublets;
and the calculation of a ratio avoids high scores for non-doublet cells in highly abundant subpopulations.
We see the function in action below.
To speed up the density calculations, `computeDoubletDensity()` will perform a PCA on the log-expression matrix, and we perform some (optional) parametrization to ensure that the computed PCs are consistent with that from our previous analysis on this dataset.
``` r
library(BiocSingular)
set.seed(100)
# Setting up the parameters for consistency with denoisePCA();
# this can be changed depending on your feature selection scheme.
dbl.dens <- computeDoubletDensity(sce.mam, subset.row=top.mam,
d=ncol(reducedDim(sce.mam)))
summary(dbl.dens)
```
```
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 0.000 0.249 0.543 1.029 1.175 14.974
```
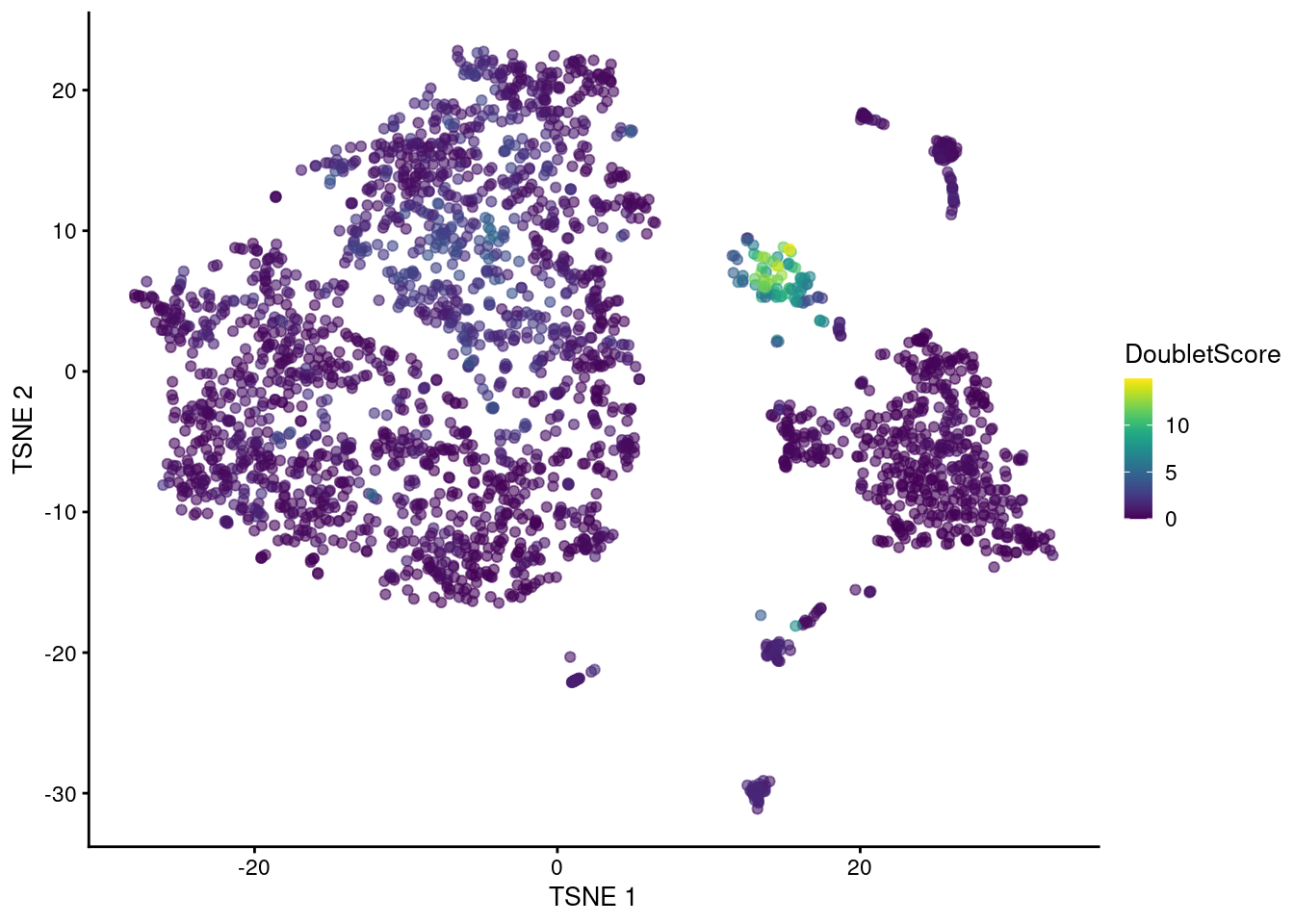
The highest doublet scores are concentrated in a single cluster of cells in the center of Figure \@ref(fig:denstsne).
``` r
sce.mam$DoubletScore <- dbl.dens
plotTSNE(sce.mam, colour_by="DoubletScore")
```
(\#fig:denstsne)t-SNE plot of the mammary gland data set. Each point is a cell coloured according to its doublet density.
We can explicitly convert this into doublet calls by identifying large outliers for the score within each sample [@pijuansala2019single].
Here, we only have one sample so the call below is fairly simple, but it can also support multiple samples if the input `data.frame` has a `sample` column.
``` r
dbl.calls <- doubletThresholding(data.frame(score=dbl.dens),
method="griffiths", returnType="call")
summary(dbl.calls)
```
```
## singlet doublet
## 2378 394
```
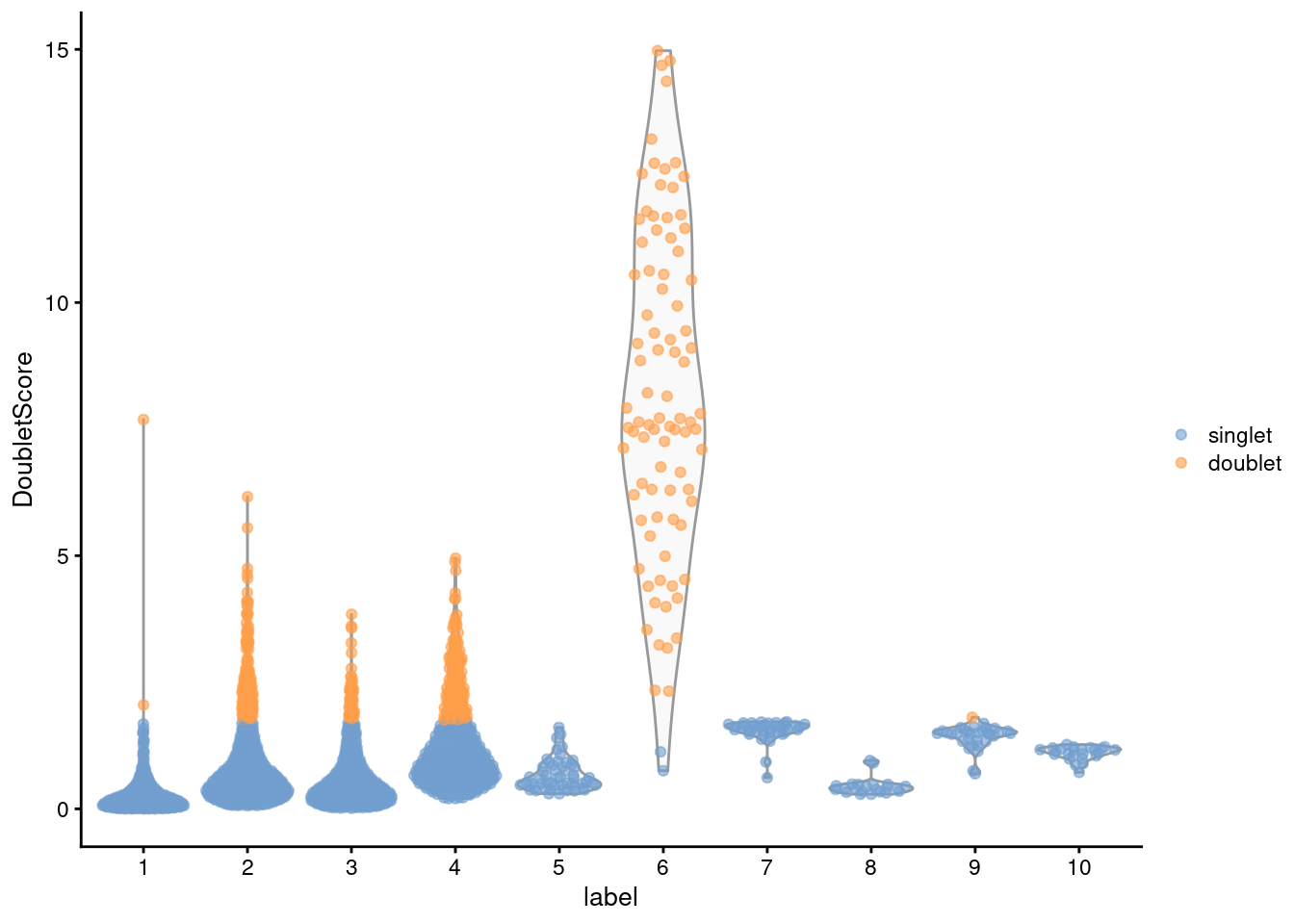
From the clustering information, we see that the affected cells belong to the same cluster that was identified using `findDoubletClusters()` (Figure \@ref(fig:densclust)), which is reassuring.
``` r
plotColData(sce.mam, x="label", y="DoubletScore", colour_by=I(dbl.calls))
```
(\#fig:densclust)Distribution of doublet scores for each cluster in the mammary gland data set. Each point is a cell and is colored according to whether it was called as a doublet.
The advantage of `computeDoubletDensity()` is that it does not depend on clusters, reducing the sensitivity of the results to clustering quality.
The downside is that it requires some strong assumptions about how doublets form, such as the combining proportions and the sampling from pure subpopulations.
In particular, `computeDoubletDensity()` treats the library size of each cell as an accurate proxy for its total RNA content.
If this is not true, the simulation will not combine expression profiles from different cells in the correct proportions.
This means that the simulated doublets will be systematically shifted away from the real doublets, resulting in doublet scores that are too low.
(As an aside, the issue of unknown combining proportions can be solved if spike-in information is available, e.g., in plate-based protocols.
This will provide an accurate estimate of the total RNA content of each cell.
To this end, spike-in-based size factors from [Basic Section 2.4](http://bioconductor.org/books/3.19/OSCA.basic/normalization.html#spike-norm) can be supplied to the `computeDoubletDensity()` function via the `size.factors.content=` argument.
This will use the spike-in size factors to scale the contribution of each cell to a doublet library.)
### Doublet classification
The `scDblFinder()` function [@germain2021scDblFinder] combines the simulated doublet density with an iterative classification scheme.
For each observed cell, an initial score is computed by combining the fraction of simulated doublets in its neighborhood with another score based on co-expression of mutually exclusive gene pairs [@bais2020scds].
A threshold is chosen that best distinguishes between the real and simulated cells, allowing us to obtain putative doublet calls among the real cells.
The threshold and scores are then iteratively refined by training a classifier on the putative calls with a variety of metrics to characterize the doublet neighborhood.
These metrics include the low-dimensional embeddings in PC space, the fraction of doublets among the $k$ nearest neighbors for a variety of $k$,
the distance to the closest real cell, the expected within-cluster doublet formation rate, the observed number of cells in each cluster, and so on.
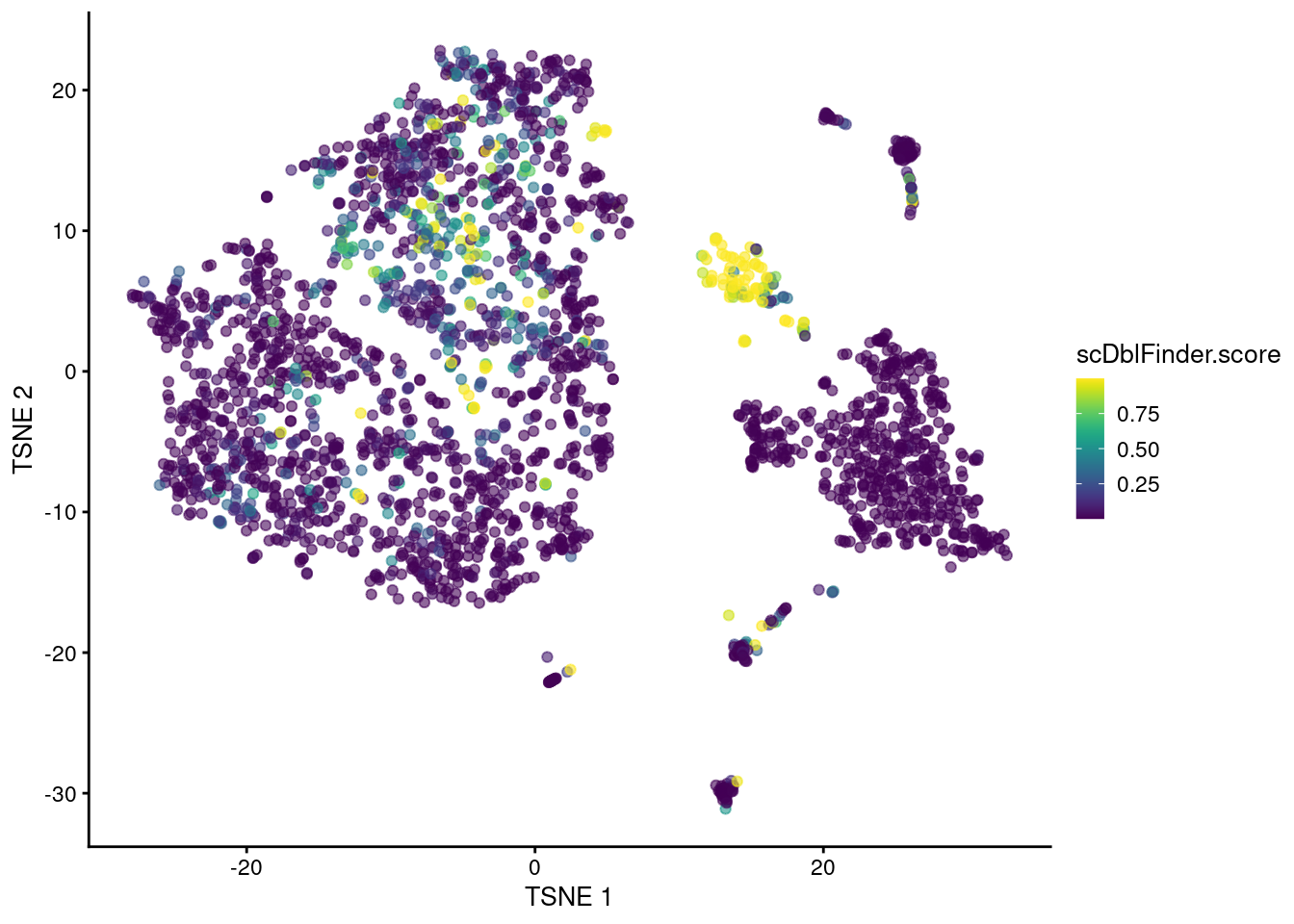
The classifier distills all of these metrics into a single score based on their learnt importance (Figure \@ref(fig:scdblfinder-tsne)).
``` r
set.seed(10010101)
sce.mam.dbl <- scDblFinder(sce.mam, clusters=colLabels(sce.mam))
plotTSNE(sce.mam.dbl, colour_by="scDblFinder.score")
```
(\#fig:scdblfinder-tsne)t-SNE plot of the mammary gland data set where each point is a cell coloured according to its `scDblFinder()` score.
We can also extract explicit doublet calls for each cell based on the final threshold from the iterative process.
``` r
table(sce.mam.dbl$scDblFinder.class)
```
```
##
## singlet doublet
## 2599 173
```
We set `clusters=` to instruct `scDblFinder()` to exclusively simulate doublets between different clusters in Figure \@ref(fig:scdblfinder-tsne).
This improves the efficiency of the simulation process by eliminating intra-cluster doublets that are indistinguishable from singlets.
Doing so is entirely optional and can be omitted if clustering information is not available or the clusters are not well-defined.
The default of `clusters=NULL` will cause `scDblFinder()` to fall back to a random simulation scheme, similar to that used by `computeDoubletDensity()`.
Compared to `computeDoubletDensity()`, `scDblFinder()` provides a more sophisticated approach that makes greater use of the information in the simulated doublets.
This can improve the performance of doublet identification in difficult scenarios, e.g., when one of the two cells contributes considerably more to the doublet, or when doublets are transcriptionally similar to real intermediate stages.
However, as with all algorithms of this class, accuracy is dependent on the correctness of the simulation process.
### Further comments
Simply removing cells with high doublet scores will typically not be sufficient to eliminate real doublets from the data set.
In some cases, only a subset of the cells in the putative doublet cluster actually have high scores, and removing these would still leave enough cells in that cluster to mislead downstream analyses.
In fact, even defining a threshold on the doublet score is difficult as the interpretation of the score is relative.
There is no general definition for a fixed threshold above which libraries are to be considered doublets.
We recommend interpreting these scores in the context of cluster annotation.
All cells from a cluster with a large average doublet score should be considered suspect, and close neighbors of problematic clusters should be treated with caution.
A cluster containing only a small proportion of high-scoring cells is safer, though this prognosis comes with the caveat that true doublets often lie immediately adjacent to their source populations and end up being assigned to the same cluster.
It is worth confirming that any interesting results of downstream analyses are not being driven by those cells, e.g., by checking that DE in an interesting gene is not driven solely by cells with high doublet scores.
While clustering is still required for interpretation, the simulation-based strategy is more robust than `findDoubletClusters()` to the quality of the clustering as the scores are computed on a per-cell basis.
## Doublet detection in multiplexed experiments
### Background
For multiplexed samples [@kang2018multiplexed;@stoeckius2018hashing], we can identify doublet cells based on the cells that have multiple labels.
The idea here is that cells from the same sample are labelled in a unique manner, either implicitly with genotype information or experimentally with hashing tag oligos (HTOs).
Cells from all samples are then mixed together and the multiplexed pool is subjected to scRNA-seq, avoiding batch effects and simplifying the logistics of processing a large number of samples.
Importantly, most per-cell libraries are expected to contain one label that can be used to assign that cell to its sample of origin.
Cell libraries containing two labels are thus likely to be doublets of cells from different samples.
To demonstrate, we will use some data from the original cell hashing study [@stoeckius2018hashing].
Each sample's cells were stained with an antibody against a ubiquitous surface protein, where the antibody was conjugated to a sample-specific HTO.
Sequencing of the HTO-derived cDNA library ultimately yields a count matrix where each row corresponds to a HTO and each column corresponds to a cell barcode.
``` r
library(scRNAseq)
hto.sce <- StoeckiusHashingData(mode="hto")
dim(hto.sce)
```
```
## [1] 8 65000
```
### Identifying inter-sample doublets
Before we proceed to doublet detection, we simplify the problem by first identifying the barcodes that contain cells.
This is most conventionally done using the gene expression matrix for the same set of barcodes, as shown in Section \@ref(qc-droplets).
Here, though, we will keep things simple and apply `emptyDrops()` directly on the HTO count matrix.
The considerations are largely the same as that for gene expression matrices; the main difference is that the default `lower=` is often too low for deeply sequenced HTOs, so we instead estimate the ambient profile by excluding the top `by.rank=` barcodes with the largest totals (under the assumption that no more than `by.rank=` cells were loaded).
The barcode-rank plots are quite similar to what one might expect from gene expression data (Figure \@ref(fig:hash-barcode-rank)).
``` r
library(DropletUtils)
set.seed(101)
hash.calls <- emptyDrops(counts(hto.sce), by.rank=40000)
is.cell <- which(hash.calls$FDR <= 0.001)
length(is.cell)
```
```
## [1] 21780
```
``` r
par(mfrow=c(1,2))
r <- rank(-hash.calls$Total)
plot(r, hash.calls$Total, log="xy", xlab="Rank", ylab="Total HTO count", main="")
hist(log10(hash.calls$Total[is.cell]), xlab="Log[10] HTO count", main="")
```
(\#fig:hash-barcode-rank)Cell-calling statistics from running `emptyDrops()` on the HTO counts in the cell hashing study. Left: Barcode rank plot of the HTO counts in the cell hashing study. Right: distribution of log-total counts for libraries identified as cells.
We then run `hashedDrops()` on the subset of cell barcode libraries that actually contain cells.
This returns the likely sample of origin for each barcode library based on its most abundant HTO,
using abundances adjusted for ambient contamination in the `ambient=` argument.
(The adjustment process itself involves a fair number of assumptions that we will not discuss here; see `?hashedDrops` for more details.)
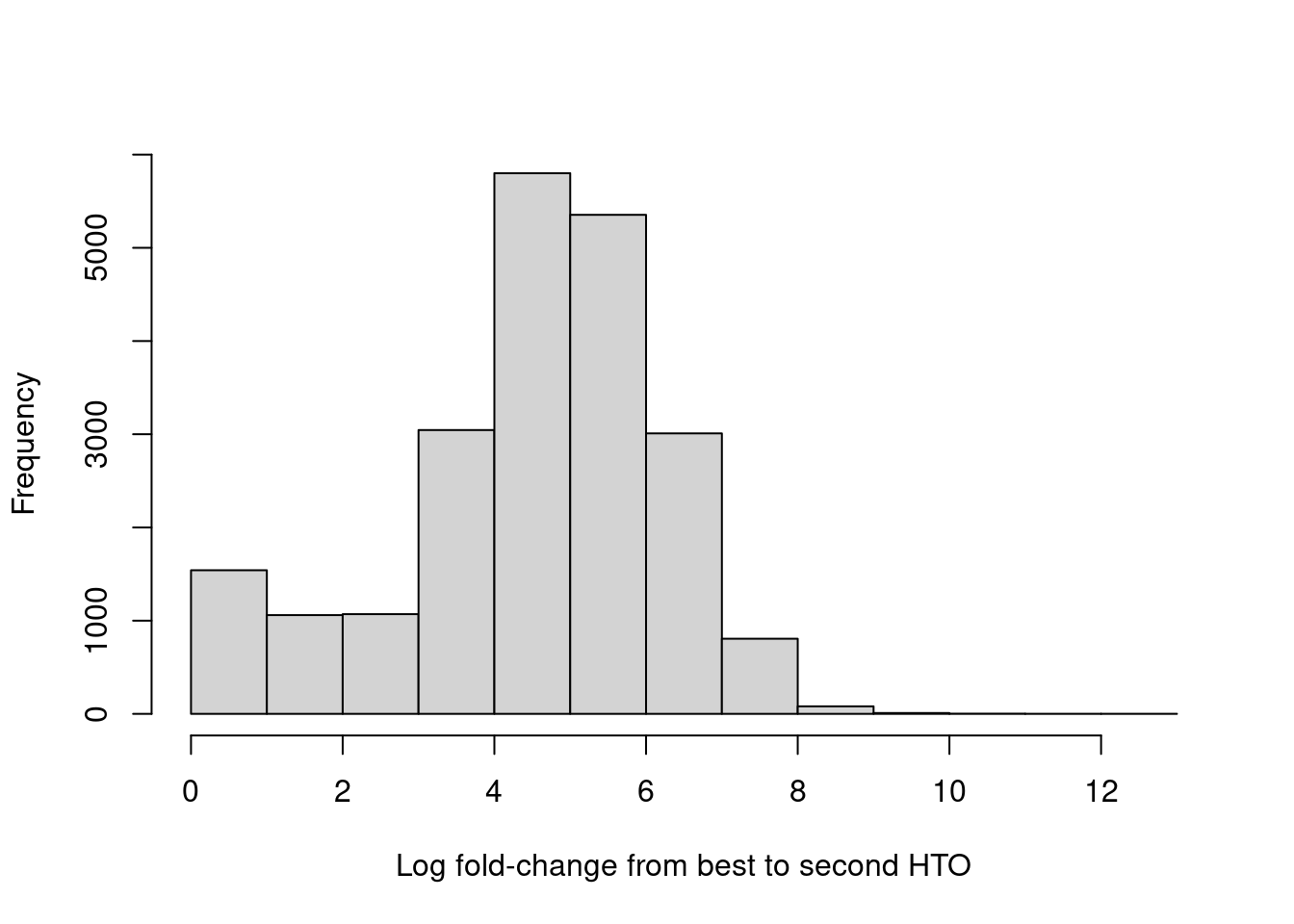
For quality control, it returns the log-fold change between the first and second-most abundant HTOs in each barcode libary (Figure \@ref(fig:hto-1to2-hist)), allowing us to quantify the certainty of each assignment.
Confidently assigned singlets are marked using the `Confident` field in the output.
``` r
hash.stats <- hashedDrops(counts(hto.sce)[,is.cell],
ambient=metadata(hash.calls)$ambient)
hist(hash.stats$LogFC, xlab="Log fold-change from best to second HTO", main="")
```
(\#fig:hto-1to2-hist)Distribution of log-fold changes from the first to second-most abundant HTO in each cell.
``` r
# Raw assignments:
table(hash.stats$Best)
```
```
##
## 1 2 3 4 5 6 7 8
## 2703 3276 2752 2782 2493 2381 2586 2807
```
``` r
# Confident assignments based on (i) a large log-fold change
# and (ii) not being a doublet, see below.
table(hash.stats$Best[hash.stats$Confident])
```
```
##
## 1 2 3 4 5 6 7 8
## 2349 2779 2457 2275 2090 1994 2176 2458
```
Of greater interest here is how we can use the hashing information to detect doublets.
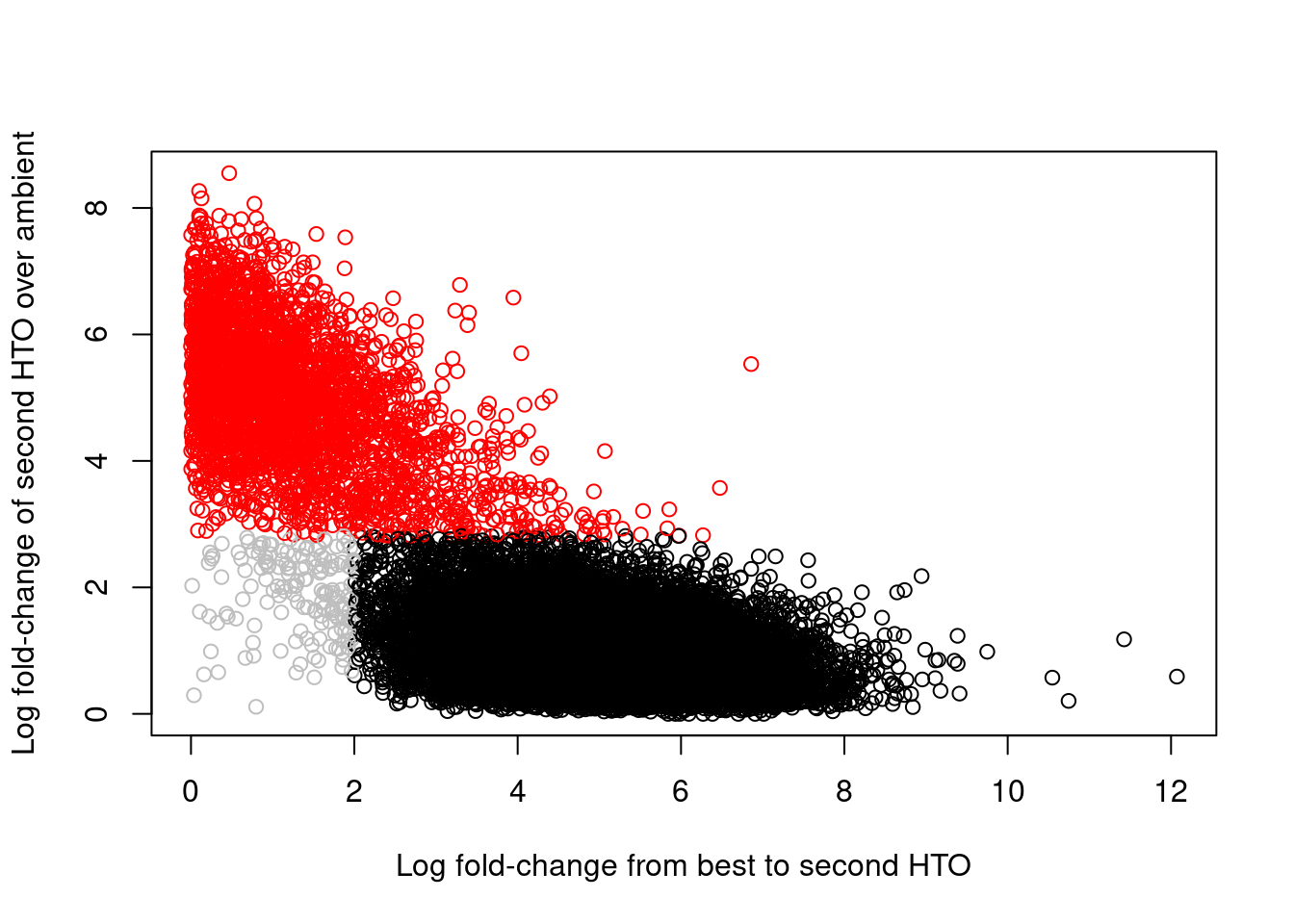
This is achieved by reporting the log-fold change between the count for the second HTO and the estimated contribution from ambient contamination.
A large log-fold change indicates that the second HTO still has an above-expected abundance, consistent with a doublet containing HTOs from two samples.
We use outlier detection to explicitly identify putative doublets as those barcode libraries that have large log-fold changes;
this is visualized in Figure \@ref(fig:hto-2to3-hash), which shows a clear separation between the putative singlets and doublets.
``` r
summary(hash.stats$Doublet)
```
```
## Mode FALSE TRUE
## logical 18742 3038
```
``` r
colors <- rep("grey", nrow(hash.stats))
colors[hash.stats$Doublet] <- "red"
colors[hash.stats$Confident] <- "black"
plot(hash.stats$LogFC, hash.stats$LogFC2,
xlab="Log fold-change from best to second HTO",
ylab="Log fold-change of second HTO over ambient",
col=colors)
```
(\#fig:hto-2to3-hash)Log-fold change of the second-most abundant HTO over ambient contamination, compared to the log-fold change of the first HTO over the second HTO. Each point represents a cell where potential doublets are shown in red while confidently assigned singlets are shown in black.
### Guilt by association for unmarked doublets
One obvious limitation of this approach is that doublets of cells marked with the same HTO are not detected.
In a simple multiplexing experiment involving $N$ samples with similar numbers of cells,
we would expect around $1/N$ of all doublets to involve cells from the same sample.
For typical values of $N$ of 5 to 12, this may still be enough to cause the formation of misleading doublet clusters even after the majority of known doublets are removed.
To avoid this, we recover the remaining intra-sample doublets based on their similarity with known doublets in gene expression space (hence, "guilt by association").
We illustrate by loading the gene expression data for this study:
``` r
sce.hash <- StoeckiusHashingData(mode="human")
# Subsetting to all barcodes detected as cells. Requires an intersection,
# because `hto.sce` and `sce.hash` are not the same dimensions!
common <- intersect(colnames(sce.hash), rownames(hash.stats))
sce.hash <- sce.hash[,common]
colData(sce.hash) <- hash.stats[common,]
sce.hash
```
```
## class: SingleCellExperiment
## dim: 27679 20828
## metadata(0):
## assays(1): counts
## rownames(27679): A1BG A1BG-AS1 ... hsa-mir-8072 snoU2-30
## rowData names(0):
## colnames(20828): ACTGCTCAGGTGTTAA ATGAGGGAGATGTTAG ... CACCAGGCACACAGAG
## CTCGGAGTCTAACTCT
## colData names(7): Total Best ... Doublet Confident
## reducedDimNames(0):
## mainExpName: NULL
## altExpNames(0):
```
For each cell, we calculate the proportion of its nearest neighbors that are known doublets.
Intra-sample doublets should have high proportions under the assumption that their gene expression profiles are similar to inter-sample doublets involving the same combination of cell states/types.
Unlike in Section \@ref(doublet-simulation), the use of experimentally derived doublet calls avoids any assumptions about the relative quantity of total RNA or the probability of doublet formation across different cell types.
``` r
# Performing a quick-and-dirty analysis to get some PCs to use
# for nearest neighbor detection inside recoverDoublets().
library(scran)
sce.hash <- logNormCounts(sce.hash)
dec.hash <- modelGeneVar(sce.hash)
top.hash <- getTopHVGs(dec.hash, n=1000)
set.seed(1011110)
sce.hash <- runPCA(sce.hash, subset_row=top.hash, ncomponents=20)
# Recovering the intra-sample doublets:
hashed.doublets <- recoverDoublets(sce.hash, use.dimred="PCA",
doublets=sce.hash$Doublet, samples=table(sce.hash$Best))
hashed.doublets
```
```
## DataFrame with 20828 rows and 3 columns
## proportion known predicted
##
## 1 0.10 TRUE FALSE
## 2 0.02 FALSE FALSE
## 3 0.14 FALSE FALSE
## 4 0.08 FALSE FALSE
## 5 0.18 FALSE FALSE
## ... ... ... ...
## 20824 0.04 FALSE FALSE
## 20825 0.04 FALSE FALSE
## 20826 0.02 FALSE FALSE
## 20827 0.04 FALSE FALSE
## 20828 0.10 FALSE FALSE
```
The `recoverDoublets()` function also returns explicit intra-sample doublet predictions based on the doublet neighbor proportions.
Given the distribution of cells across multiplexed samples in `samples=`, we estimate the fraction of doublets that would not be observed from the HTO counts.
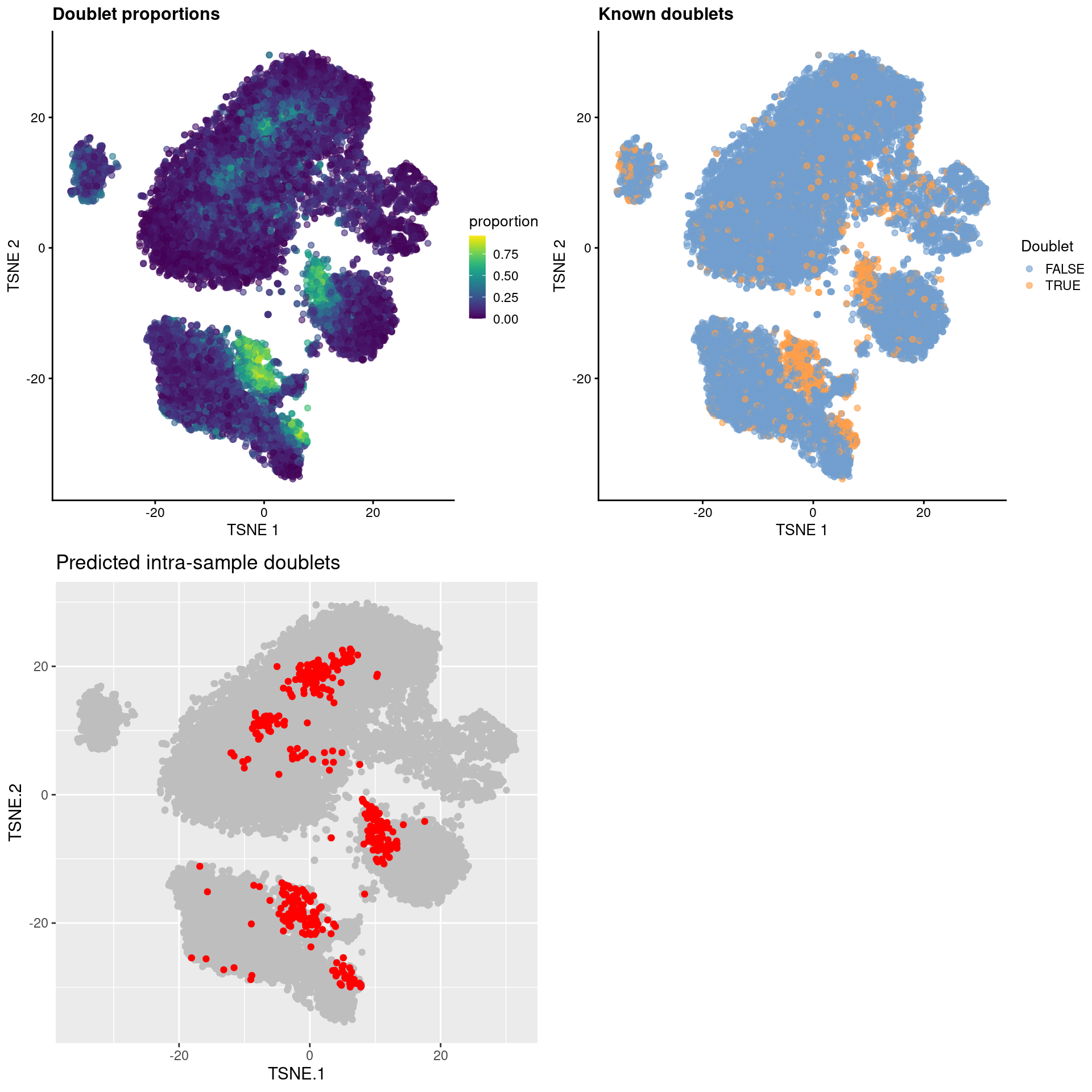
This is converted into an absolute number based on the number of observed doublets; the top set of libraries with the highest proportions are then marked as intra-sample doublets (Figure \@ref(fig:tsne-hash))
``` r
set.seed(1000101001)
sce.hash <- runTSNE(sce.hash, dimred="PCA")
sce.hash$proportion <- hashed.doublets$proportion
sce.hash$predicted <- hashed.doublets$predicted
gridExtra::grid.arrange(
plotTSNE(sce.hash, colour_by="proportion") + ggtitle("Doublet proportions"),
plotTSNE(sce.hash, colour_by="Doublet") + ggtitle("Known doublets"),
ggcells(sce.hash) +
geom_point(aes(x=TSNE.1, y=TSNE.2), color="grey") +
geom_point(aes(x=TSNE.1, y=TSNE.2), color="red",
data=function(x) x[x$predicted,]) +
ggtitle("Predicted intra-sample doublets"),
ncol=2
)
```
(\#fig:tsne-hash)$t$-SNE plots for gene expression data from the cell hashing study, where each point is a cell and is colored by the doublet proportion (top left), whether or not it is a known inter-sample doublet (top right) and whether it is a predicted intra-sample doublet (bottom left).
As an aside, it is worth noting that even known doublets may not necessarily have high doublet neighbor proportions.
This is typically observed for doublets involving cells of the same type or state, which are effectively intermixed in gene expression space with the corresponding singlets.
The latter are much more abundant in most (well-controlled) experiments, which results in low proportions for the doublets involved (Figure \@ref(fig:doublet-prop-hash-dist)).
This effect can generally be ignored given the mostly harmless nature of these doublets.
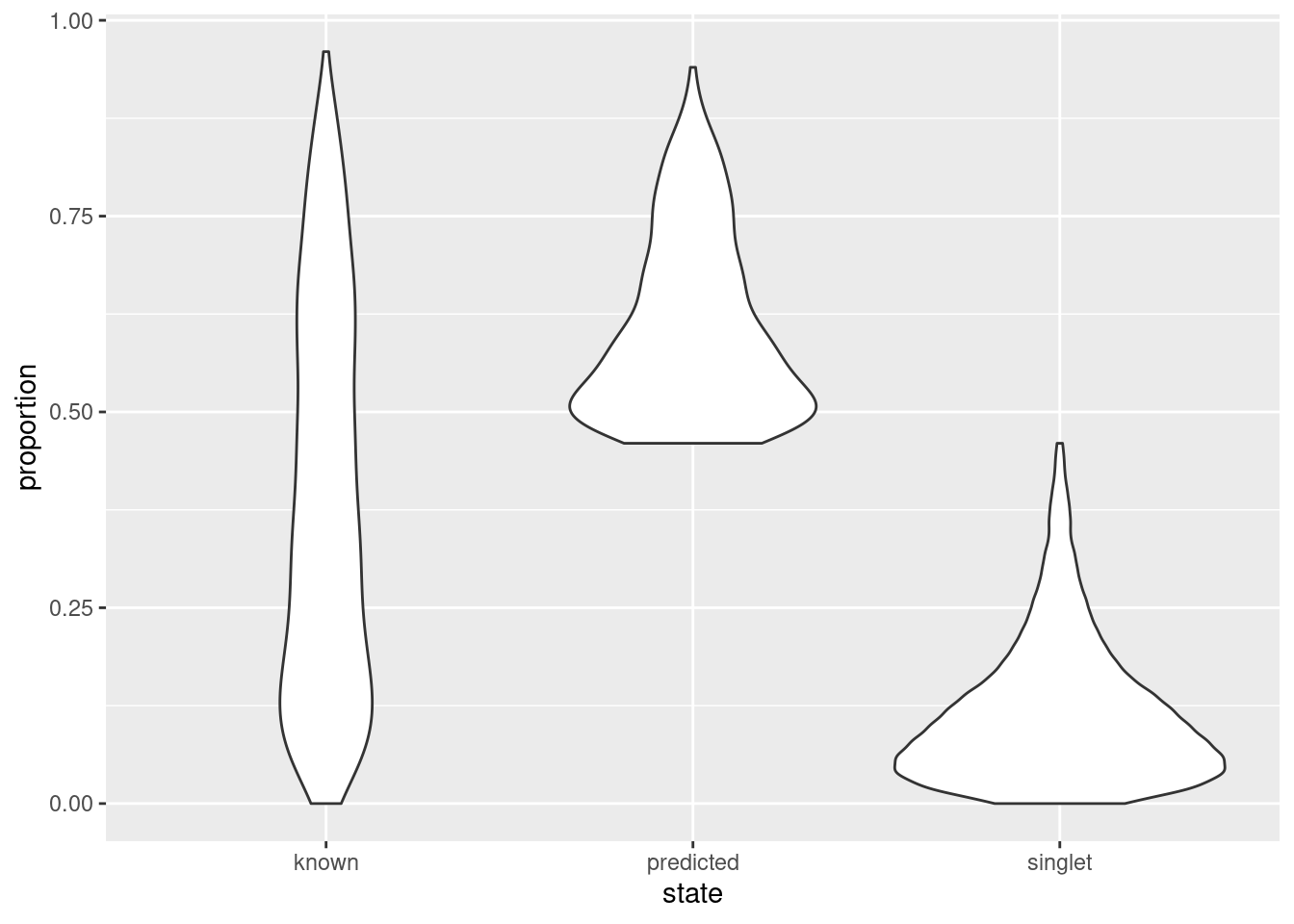
``` r
state <- ifelse(hashed.doublets$predicted, "predicted",
ifelse(hashed.doublets$known, "known", "singlet"))
ggplot(as.data.frame(hashed.doublets)) +
geom_violin(aes(x=state, y=proportion))
```
(\#fig:doublet-prop-hash-dist)Distribution of doublet neighbor proportions for all cells in the cell hashing study, stratified by doublet detection status.
## Further comments
Doublet detection procedures should only be applied to libraries generated in the same experimental batch.
It is obviously impossible for doublets to form between two cells that were captured separately.
Thus, some understanding of the experimental design is required prior to the use of the above functions.
This avoids unnecessary concerns about the validity of batch-specific clusters that cannot possibly consist of doublets.
It is also difficult to interpret doublet predictions in data containing cellular trajectories.
By definition, cells in the middle of a trajectory are always intermediate between other cells and are liable to be incorrectly detected as doublets.
Some protection is provided by the non-linear nature of many real trajectories, which reduces the risk of simulated doublets coinciding with real cells in `computeDoubletDensity()`.
One can also put more weight on the relative library sizes in `findDoubletClusters()` instead of relying solely on `N`,
under the assumption that sudden spikes in RNA content are unlikely in a continuous biological process.
The best solution to the doublet problem is experimental - that is, to avoid generating them in the first place.
This should be a consideration when designing scRNA-seq experiments, where the desire to obtain large numbers of cells at minimum cost should be weighed against the general deterioration in data quality and reliability when doublets become more frequent.
## Session Info {-}